Why Google's cache should not be used for SEO
For a long time, SEOs have relied on Google's cached version of pages to answer questions such as Did Google crawl this page? When? Can the bot see the content? etc. However, this feature (if used) must be used with caution and here's why.
According to Google, "Cached links show you what a webpage looked like the last time Google visited it." Unfortunately, this statement is not true, or at least it's incomplete.
Below is a screenshot of Google's cached version of a webpage. It gives us three different pieces of information: the URL that has been cached, when, and a snapshot. You can also see the HTML source code that was cached by clicking "View source".
However, none of this information is reliable, relevant or even useful.
The URL
When accessing the cached version of a page, Google may return a cached page, but not the one you requested.
Google only caches "indexable" pages. Non-indexable pages are usually URLs that have a noindex tag, redirect to another URL, have a non-self-referencing canonical tag, and/or are judged as a soft 404 or duplicate content.
For example, Moz's UGC category pages have canonical tags pointing to their Main Blog equivalent URLs. Thanks to those tags, /ugc/category/ URLs are not indexed (they used to be), they do not rank and, hopefully, any equity (or PageRank) is transfered to the /blog/category/ URLs.
However, those UGC URLs exist, they are accessible, and they render. Googlebot crawls them but because they are not indexable, they are not cached. Therefore, as shown in the screenshot below, when accessing the cached version of a Moz's /ugc/category/ URL, you get the cached version of the /blog/category/ page.
Another example is a page we published on TechnicalSEO.com. The page explains what the 404 status code is and what are soft 404s. Because of the verbiage in the copy, this particular page is considered as a soft 404 by Googlebot. Result? The page is not indexed and Google has not cached it.
If for some reason, a page is "not indexable", it's likely that it won't be cached so you won't get any data from Google's cache. You will get data for the more authoritative URL (in the case of redirect, canonical or duplicate content) or nothing at all (in the case of soft 404 or noindex tag). However, it doesn't mean that the page has not been crawled.
Note: For a minute I asked myself, "What if the absence of information is actually valuable insight? Why the page isn't cached? Why is it not indexable? How can we gather and leverage this information from Google's cache?" Then two things quickly came to my mind:
Reason-not-to-use-Google's-cache-as-an-SEO-tool #1: Google doesn't cache and return data for all URLs.
The Snapshot
By now, we all know that Google is able to execute JavaScript and to fully render webpages. Therefore, you cannot rely on Google's cache to determine what Google can "see" or not. Google's cache doesn't always show "what a webpage looked like the last time Google visited it."
Here is the cache version of TechnicalSEO.com:
Google caches the HTML source code of a page, not an HTML snapshot after JavaScript has been executed. If the page is not using any kind of JavaScript to fully render, then yes, the cached version would reflect what the page looks like. However, if your site is built with AngularJS, or any other JavaScript framework, it's likely that the cached page from Google doesn't represent the actual page as seen by users.
The explanation in this case is quite simple. The routing system of AngularJS, when using the HTML5 mode (pushState), relies on the URL itself to make the AJAX call in order to serve the right content on the right page.
- When accessing the site, the URL is http://technicalseo.com/, the AngularJS app "recognizes" the URL and displays the content associated with it.
- When accessing the cached version from Google, the URL is http://webcache.googleusercontent.com/search?q=cache:technicalseo.com, so AngularJS, running in the background, is not able to go through with the AJAX request. Other than some style/template elements, the cached page is blank. It doesn't mean that Google is not able to fully render the page and "see" the content.
Here are GSC Fetch and Render's results:
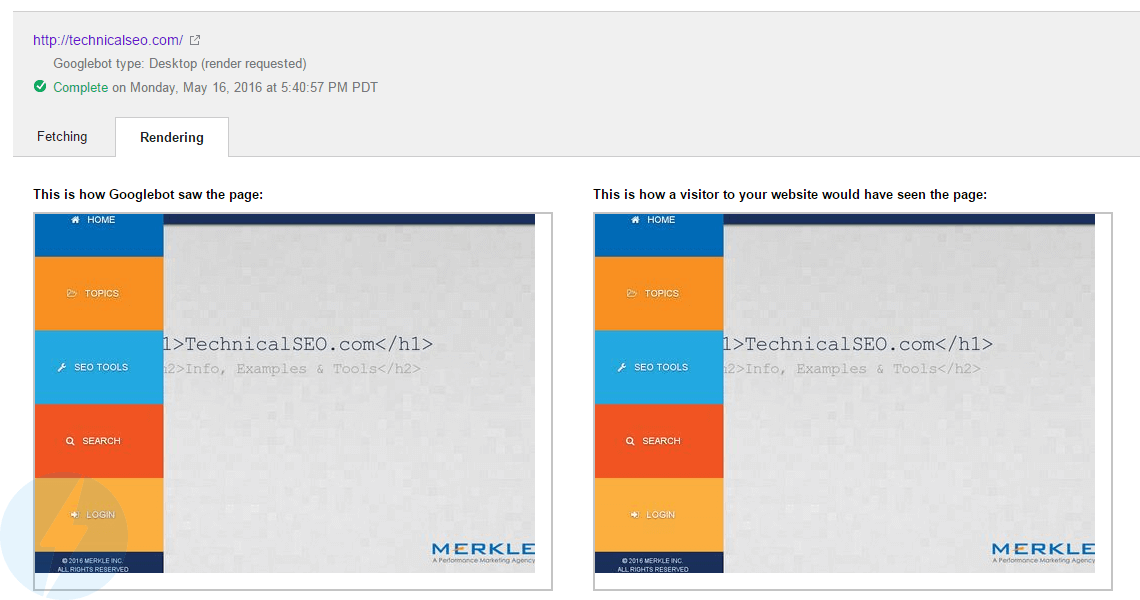
Google can obviously render the content of the site properly.
To verify if Google can access the content of your pages and make sure you don't get false negatives, use Fetch as Google within Google Search Console, not Google's cache.
Reason-not-to-use-Google's-cache-as-an-SEO-tool #2: the snapshot can misrepresent the page.
The Timestamp
Knowing when Google last crawled a page is definitely useful. For example, if a page or site has not been crawled in a while, it would explain why a new piece of content is not ranking or why your old page titles are still showing up in search results.
Unfortunately, you can't really get this information from Google's cache. The last time the page was cached might be different than the last time the page was crawled.
Also, as explained earlier, if your page is deemed "not indexable", you won't even know when Google last cached it.
Use your server logs to get a more accurate picture of bots traffic. You'll know exactly when Googlebot crawls your pages.
Reason-not-to-use-Google's-cache-as-an-SEO-tool #3: the timestamp doesn't mean anything relevant for SEO.
Conclusion
The information provided by Google's cache, when available, is useless: not all URLs are cached, the snapshot can be inaccurate and the timestamp represents the last time the page was cached, not crawled.
To answer the questions: Did Google crawl this page? When? Can the bot see the content? use GSC's Fetch and Render tool and analyze your log files.